
MAIN FEATURES OF SQL SERVER 2014
- New In-Memory OLTP Engine
- Enhanced Windows Server 2012 Integration
- Enhancements to AlwaysOn Availability Groups
- Enhancements to BackupsLock priority of online operationsUpdateable columnstore indexes
- Resource Governor for I/O
- Enhanced Windows Server 2012 Integration
- Enhancements to Backups
- Lock priority of online operations
- You can now specify a lock priority for online re-indexing.
In previous versions of SQL Server, long-running queries could block re-indexing operations and may fails. In SQL Server 2014, you can specify how your re-index operation will handle being blocked. You specify how long it will wait and what to do when the wait is over. Will you have it follow traditional behavior and wait indefinitely? Will you have it terminate and move to the next table? Or will you kill the blocking query, so your re-indexing can complete? It's your choice.
Updateable columnstore indexes
Columnstore indexes in SQL Server 2014 brought a dramatic boost to data warehouse performance With SQL Server 2014, now they can. - This means you no longer have to drop and re-create columnstore indexes every time you need to load your warehouse tables. Not only that, but updateability also means you may be able to look at columnstore indexes for certain OLTP applications.
The caveat is that you must have a clustered columnstore index on the table.
Note:- Non-clustered columnstores aren't supported.select 'sarath','user','1313 reddinton bird Rpad' 'uk','75810'; - Resource Governor for I/O
Disk I/O is typically the most constrained resource of a database system, and often a large query will take up more precious I/O resources than you can afford. Microsoft has finally given us some control over runaway I/O.
With Resource Governor for I/O, you can now put queries into their own resource pool and limit the amount of I/O per volume they're allowed. MIN_IOPS_PER_VOLUME and MAX_IOPS_PER_VOLUME set the minimum and maximum reads or writes per second allowed by a process in a disk volume. - SQL Server Data Tools for Business Intelligence
SQL Server Data Files in Azure - Delayed durability
- SQL Server Data Files in Azure


New In-Memory OLTP Engine
The most important new feature in SQL Server 2014 is the In-Memory OLTP engine (formerly code-named Hekaton).
By moving select tables and stored procedures into memory, you can drastically reduce I/O and improve performance of your OLTP applications.
To help you evaluate how the In-Memory OLTP engine will improve your database performance, Microsoft includes the new Analysis, Migrate, and Report (AMR) tool. AMR Stands for SQL Server 2014's Analysis, Migrate, and Report Tool.
The AMR tool analyzes your database and helps you identify the tables and stored procedures that would benefit from moving them into memory.
The In-Memory OLTP engine works with a number of limitations.
For instance, not all of the data types are supported. Some of the data types that aren't supported for memory-optimized tables include geography, hierarchyid, image, text, ntext, varchar(max), and xml.
In addition, several database features can't be used with this new features like Database mirroring, snapshots, computed columns, triggers, clustered indexes, identity columns, FILESTREAM storage, and FOREIGN KEY, CHECK, and UNIQUE constraints are not supported.
SQL Server 2014 provides improved integration with Windows Server 2012 R2 and Windows Server 2012. SQL Server 2014 will have the ability to scale up to 640 logical processors and 4TB of memory in a physical environment. It can scale up to 64 virtual processors and 1TB of memory when running on a virtual machine (VM).
SQL Server 2014 also provides a new solid state disk (SSD) integration capability that enables you to use SSD storage to expand SQL Server 2014's buffer pool.
Enhancements to AlwaysOn Availability Groups
SQL Server 2014's AlwaysOn Availability Groups has been enhanced with support for additional secondary replicas and Windows Azure integration. First introduced with SQL Server 2012, AlwaysOn Availability Groups boosted SQL Server availability by providing the ability to protect multiple databases with up to four secondary replicas. In SQL Server 2014, Microsoft has enhanced AlwaysOn integration by expanding the maximum number of secondary replicas from four to eight.
Azure VMs for Availability replicas
With SQL Server 2014, you can define an Availability Group replica that resides in Azure. When a primary failure happens, you have to fail over manually, but you will be up and running very quickly.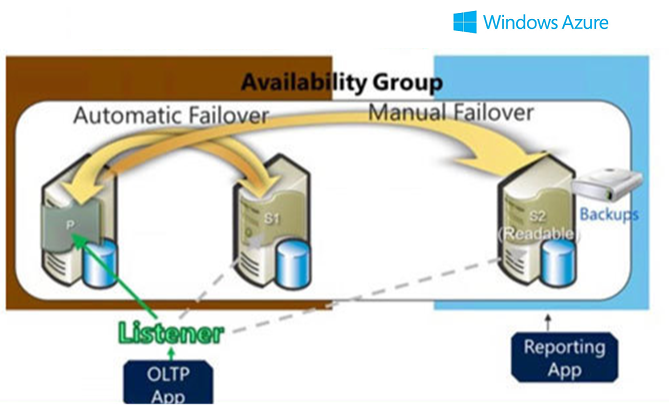
Database backups in SQL Server now support built-in database encryption. Previous releases all required a third-party product to encrypt database backups.
--right method
create clustered columnstore index samplecolumnstore on dbo.sampletable;
insert sampletable
select 'tom','user','1313 reddinton bird ln' 'uk','75810';
--wrong method
create nonclustered columnstore index sampleind_name on dbo.sampletable(colname);
insert sampletable
---Admin have 20 iops/sec reserved and can take up to 100 iops/sec
create resource POOL POOLADMIN
with
(
MIN_IOPS_PER_VOLUME = 20,
MAX_IOPS_PER_VOLUME = 100
);
CREATE WORKLOAD GROUP EMEADBA
USING POOLADMIN;
Delayed durability
In SQL Server, changes to data are written to the log first. This is called write ahead logging (WAL). Control is not returned to the application until the log record has been written to disk (a process referred to as "hardening"). Delayed durability allows you to return control back to the application before the log is hardened. This can speed up transactions if you have issues with log performance. Nothing is free, though, and here you sacrifice recoverability. Should the database go down before the log is committed to disk, then you lose those transactions forever. It may be worth the risk if your log performance is severely degrading application response times.
Incremental statistics
Updating statistics in SQL Server is the very definition of redundant work. Whenever statistics need to be rebuilt, you cannot just update the new items. You have to update everything.
This means a table with 400 million rows and only 30 million changes will need to update all 400 million rows in order to pick up those changes. Incremental statistics in SQL Server 2014 allow you to update just those rows that have changed and merge them with what's already there. This can have a big impact on query performance in some configurations.
--Define incremental statistics when the index is created.
CREATE INDEX INDEX_NAME ON DBO.TABLENAME(COLNAME)
WITH
( ONLINE=ON,STATISTICS_INCREMENTAL = ON)
--Also when the statistics are created manually
CREATE STATISTICS STATSAMPLE ON DBO.TABLENAME(COLNAME)
WITH FULLSCAN, INCREMENTAL = ON
Previously known as Business Intelligence Development Studio (BIDS) and SQL Server Data Tools (SSDT), the new SQL Server Data Tools for BI (SSDT BI) is used to create SQL Server Analysis Services (SSAS) models, SQL Server Reporting Services (SSRS) reports, and SQL Server Integration Services (SSIS) packages. SSDT BI is based on Microsoft Visual Studio 2012 and supports SSAS and SSRS for SQL Server 2014 and earlier
Data Files in Azure is just what it sounds like:
Your database runs locally in your data center, while the database files themselves live in an Azure blob container.
This will give advantages in DR and migration. But depending on the size of the database and its workload, the potential performance cost of pushing the data for every transaction across the Internet could be prohibitive.
This feature may be to store the data files in an Azure VM in the same data center. This can also get you around the current limitation of having only 16 mounted disks in an Azure VM.
Sample Script :-
CREATE CREDENTIAL [HTTPS://SAMPLESYKES.BLOB.CORE.EMEA.NET/SAMPLE]
WITH IDENTITY 'SHARED_ACCESS'
SECRET ='ST-SAMPLEAZURE-ABCD-JYOLEJSEHTHI-2014'
GO
CREATE DATABASE SAMPLEAZURE ON PRIMARY
( NAME = 'SAMPLEAZURE', FILENAME = 'HTTPS://SAMPLESYKES.BLOB.CORE.EMEA.NET/SAMPLE/SAMPLEAZURE.MDF' ,
SIZE = 3264KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = 'SAMPLEAZURE_LOG', FILENAME = 'HTTPS://SAMPLESYKES.BLOB.CORE.EMEA.NET/SAMPLE/SAMPLEAZURE1_LOG.MDF' ,
SIZE = 1088KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
No comments:
Post a Comment